Final Project - Stage 3 - Wrap Up
So, in the previous post we saw an average of 2% improvement building with -Ofast -march -mtune compiler options.
To see if it could be improved further I looked at the codes, hoping to find that one place where I can optimize.
Long story short, I was not able to optimize.
This is what happened:
In the beginning when I decided to take bzip2 for the project I read it's introduction on the bzip2 website.
Here it is mentioned that the bzip2 was built using Burrows-Wheeler Transform and Huffman algorithm to create lossless compression.
I had no idea what these algorithms are about and how they work, so I Googled them in hopes to find some explanation in plain English.
After watching these videos it is pretty clear that there is no way I can improve these algorithms. These algorithms have been battle tested and have proved to work very well, so well that BWT is used for human DNA sequencing.
Then this is it, there is nothing I can do. Except, as mentioned in the Huffman video the block size can affect the performance.
So, my quest started looking where the block size is defined. Strangely it's not globally defined in bzip2, Ctrl+shift+f on VS Code didn't give me anything.
Let's look at the manual, bzip2 was nice enough to include a manual about bzip2, and see if we can find something about where/how block size is defined.
After reading through the manual and the code it looks like the block size is defined as 100000 * blockSize100k.
The blockSize100k is a variable holding number from 1 to 9.
bzip2 has a flag where a user can specify the block size from 100,000 to 900,000 by using -1, -2, ..., -9 or --fast, --best where --fast is 100,000 and --best is 900,000.
So, in theory if I change this 100,000 to a larger number it should work better.
Time to test the theory.
bzlib.c
Before:

After:

Here I changed the block size from 100,000 to 1,000,000. In theory this should improve Huffman tree, therefore improve the compression.
Test Result:

hmm...
This error looks like some kind of bug with memory size when we changed the block size from 100,000 to 1 million. Maybe 1 million was too big, so I tried with 200,000 but this also displayed same error output.
I'm starting to think that it's not as easy as just changing that 100,000 to whatever value.
I spent hours and hours trying to find where in the code that would cause this error. My thought was that:
1) somewhere in the program it looks at the size of the block
2) based on the size of the block, the object that holds compressed symbols changes, or
3) the conversion table size is changed, or
4) size of a buffer is changed
After numerous hours I was not able to find the code/function that would take of larger block size value.
It was very disappointing that I was not able to figure this out. I really wanted to test my theory, but it was just too complex of codes for me to tinker with. This almost makes me want to go to University and study Computer Science, almost.
Since I failed to test my theory I thought I would have fun and find a piece of code that I know I can writer differently.
I found some pieces of codes that I think it could be re-written in compress.c
Line 197
Before

Looking at this code, I thought it
1) it's redundant to have rtmp2 re-initialized every iteration
2) ryy_j++ could prob be part of while condition
then, if these two theory makes sense and the changes does not change the value after the while loop, then SIMD could probably used for the rtmp2=rtmp; rtmp = *ryy_j; *ryy_j = rtmp2;, since definition of SIMD is Single Instruction Multiple Data.
So the code looks like this after

Line 370
Before
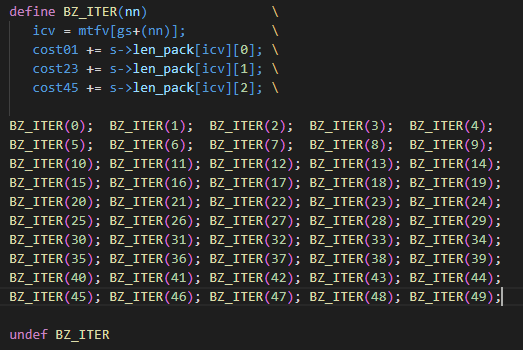
To be honest, I have no idea what's going on in this code.
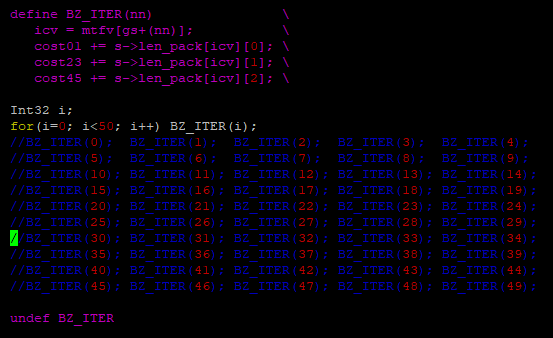
Looking at the code though, since the parameter value is sequence from 0 to 49, would it make any difference if this was put in a for loop?
Let's find out.
This is the code after:
Line 415
Before
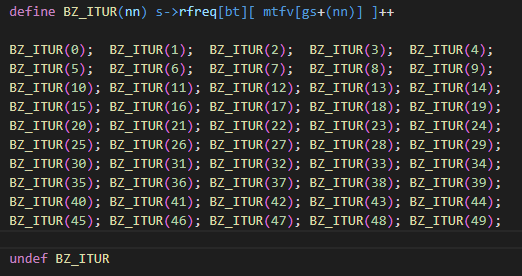
Again, no idea what's going on but the pattern is same as the code on Line 370.
I'll also put this into a for loop and see if anything changes.
This is the code after:

The Build
For testing the changed codes I re-compiled the program with the -Ofast -march -mtune options.
The program compiled without any errors, but this warning message was shown.

Hopefully it still works.
Only one way to find out, it's compress the files.
Fingers crossed....
.
.
.
.
.
.
Test Results

?????????????????????
????????????????
Ok, looks like something worked for the better.
hmm........
..........
......
...
I wish I could explain this result, I really do.
I wasn't expecting anything, it's surprising to see such difference.
BTW, the difference is calculated using the original value.
I'm going to take a wild blind guess that it's SIMD at work in the while loop.
Now, the true test, can a file be compressed and decompressed without any error?
When it was optimized with just compiler options, the file was able to be compressed and decompressed without any problem. Well, this makes sense since no code was touched so if it didn't work that would be weird.
But now with the code changed, although the changes I made are not significant, it's probably a good idea to test it.
Here is how I'll be testing this.
1) compress each file (random.txt, image.jpg, final.docx) with different name
2) decompress compressed file
3) use diff to check
aarchie
Test 1 : random.txt
Test 2 : image.jpg
Test 3 : final.docx
xerxes
Test 1 : random.txt
Test 2 : image.jpg

Test 3 : final.docx

So looks like everything is good; it's compressing and decompressing without the content changing.
The program works as it should with the edited code on both aarch64 and x86_64 machines.
Conclusion
To sum up, I was able to see some improvement in the performance.
As mentioned earlier, it's disappointing not have been able to test with block size.
The program was successfully, though not by much, optimized with compiler options
(-Ofast -march -mtune).
It was really unexpected to see such improvement with the edited codes.
The improvement was about double of the -Ofast -march -mtune.
In the end I was able to reach an average of 7% on aarch64 and average of 6% on x86_64 machine.
Even if the edited version of the code is not an legitimate optimization, the compilation options alone was able to produce an average of 2% improvement on both architectures.
With this I conclude my project.
It was an journey working this project, and a quite interesting one too.
Comments
Post a Comment