Vectorization and SIMD
In this post I'll be looking at auto-vectorization using gcc and how SIMD instructions are used in vectorization of code.
SIMD (single instruction multiple data) performs the operation once on multiple data sets.
 The image above compares the difference of addition operation on multiple data. On the left, the normal instruction, performs addition operation multiple times until all data pair are added. On the right, SIMD instruction, performs one addition operation on multiple data.
The image above compares the difference of addition operation on multiple data. On the left, the normal instruction, performs addition operation multiple times until all data pair are added. On the right, SIMD instruction, performs one addition operation on multiple data.
Another difference we can see is that instruction on the left is like working working individual data, whereas SIMD on the right the data looks like two vectors and outputs one vector with results.
Testing:
To see how vectorization is done using SIMD instruction I'll be compiling sample code in two different ways: 1) normal compilation 2) auto-vectorized compilation.
Code

This code does the following:








SIMD (single instruction multiple data) performs the operation once on multiple data sets.

Another difference we can see is that instruction on the left is like working working individual data, whereas SIMD on the right the data looks like two vectors and outputs one vector with results.
Testing:
To see how vectorization is done using SIMD instruction I'll be compiling sample code in two different ways: 1) normal compilation 2) auto-vectorized compilation.
Code

- Create three arrays of size 1000
- First loop populates two arrays with random numbers ranging from -1000 to 1000
- Second loop populates third array by adding first two arrays
- Third loop sums up all the values in third array
- Print out the sum
1) Normal Compilation
gcc vectorization.c -o lab6
Let's take a look at disassembly for this.


As expected, it's not optimized much but is it vectorized?
Let's compare.
2) Auto-Vectorized Compilation
Following the guide on the course website on using auto-vectorization, I was unable to get any vectorization output using -ftree-vectorizer-verbose=2 flag
After doing some digging around Google I came across two flags.
-fopt-info-vec-missed //this gives output on loops that are not vectorized
-fopt-info-vec-optimized //this gives output on loop that has been vectorized
I will compile using the second flag to see if my code will get vectorized, and if it does which loop is vectorized.
gcc -O3 -ftree-vectorize -fopt-info-vec-optimized vectorization.c -o lab6v
Yes!! Looks like my code has been vectorized. Vectorization was done on line 19, which is my second for loop.
Now the disassembly for this code:

Vectorization:

The vectorization parts are highlighted with yellow box.
Lets take a look at the list of vector registers:
Source: arm.com Page46

Let's take a look at the list of vector register sizes:
Source: arm.com Pages 55, 56
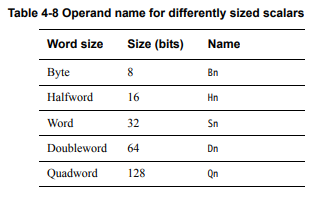

Using these tables, let's try to understand how compiler vectorized our second for loop in the sample code.
movi v1.4s, #0x0 -- move immediate value 0 into vector1 with 4 lanes, each 32-bit wide
add v0.4s, v0.4s, v2.4s -- add vector2 and vector0 and store that value in vector0.
add v1.4s, v1.4s, v0.4s -- add vector0 and vector1 and store that value in vector1.
-- arrC[j] = arrA[j] + arrB[j];
addv s1, v1.4s -- add across vector v1 and store that value into s1.
-- total += arrC[j];
Conclusion:
Vectorizing the code by using SIMD instruction have advantage where it only requires one processor to perform the operation, and this frees up other processors for other sets of instructions. The disadvantage is that not all codes can be vectorized and the codes needs to meet the criteria to be vectorized.
I'm not sure if I interpreted the vectorization instruction correctly. I'll update this post when I have more accurate interpretation.
Comments
Post a Comment